
Running DeepSeek Coder Locally: AI Programming Assistant on Consumer Hardware on RTX 4080 Super: A Journey Through WSL

"Hey, what if we made superintelligent AI without needing a data center the size of a small country?"
- Probably someone at DeepSeek during a coffee break
So there I was, reading about the latest AI models that need enough GPU power to light up Las Vegas, when DeepSeek dropped their latest bomb: a 70B parameter model that supposedly runs on... consumer hardware? Right. And my coffee machine can solve world peace.
But here's the thing - they weren't joking.
While the tech giants are out there burning through cash faster than a Tesla on Ludicrous mode (we're talking $100M+ just to train one model), DeepSeek casually walked in and did it for about $5M. That's like showing up to an F1 race with a souped-up Honda Civic... and winning.

The Secret Sauce
Their trick? They basically looked at traditional AI training and said, "You know all this extra precision? Yeah, we don't need that." Traditional models are like that friend who gives you GPS coordinates to meet at the coffee shop - down to the millimeter. DeepSeek is more like "It's the big building with the giant coffee cup on top. You can't miss it." Both get you there, but one uses way less data.
They also made their AI read like a grad student hopped up on espresso instead of a careful first-grader:
- Traditional AI: "The... cat... sat... on... the... mat..."
- DeepSeek: "The cat sat on the mat NEXT!"
The results are kind of mind-blowing:
- Costs down by 95%
- Needs 98% fewer GPUs
- Can potentially run on the same hardware you use to play Cyberpunk 2077
And the best part? It's all open source. That's right - they didn't just beat the system, they published the cheat codes.
The Windows Situation: Enter WSL
Here's the thing - I'm a Windows user. My gaming rig doubles as my workstation, and Windows is where all my favorite apps live. But there's a catch: vLLM, the engine I need to run DeepSeek, is like that cool friend who only hangs out at Linux parties.
Enter Windows Subsystem for Linux (WSL) - Microsoft's way of saying "Hey, why not both?" It's basically Linux running inside Windows, like a Russian nesting doll of operating systems. WSL lets you run Linux tools natively on Windows without the commitment of a full divorce from Microsoft. It's the tech equivalent of having your cake and eating it too.
Why is this important? Because while Windows is great for gaming and productivity, the AI community has a massive crush on Linux. Most cutting-edge AI tools, including vLLM, are built with Linux in mind. It's like trying to play a PlayStation game on an Xbox - without WSL, I would be out of luck.
The Experiment
So naturally, I did what any reasonable tech enthusiast would do: I decided to try running this beast on my RTX 4080 Super through WSL. Because why not? If DeepSeek can make AI run on gaming hardware, I want to be the guy who made it work on his gaming rig while still being able to alt-tab back to Steam.
This article documents my journey of either spectacular success or glorious failure (spoiler alert: it's complicated). Follow along as I attempt to cram a 70B parameter model into a GPU with all the subtlety of trying to fit an elephant into a Smart car, all while juggling Windows and Linux like a tech circus performer.
Setting Up WSL with Debian
First, let's set up Windows Subsystem for Linux (WSL) with Debian. Open PowerShell as Administrator and run:
wsl --install Debian
After installation, restart your computer. Upon restart, launch Debian from the Start menu. You'll be prompted to create a username and password - keep these safe as you'll need them for sudo commands.
Installing NVIDIA Drivers and CUDA
With WSL running, we need to set up NVIDIA drivers and CUDA toolkit. I used CUDA 12.8 which was the latest version at the time:
wget https://developer.download.nvidia.com/compute/cuda/12.8.0/local_installers/cuda-repo-debian12-12-8-local_12.8.0-570.86.10-1_amd64.deb
dpkg -i cuda-repo-debian12-12-8-local_12.8.0-570.86.10-1_amd64.deb
cp /var/cuda-repo-debian12-12-8-local/cuda-*-keyring.gpg /usr/share/keyrings/
apt-get update
apt-get -y install cuda-toolkit-12-8
apt-get install -y nvidia-open
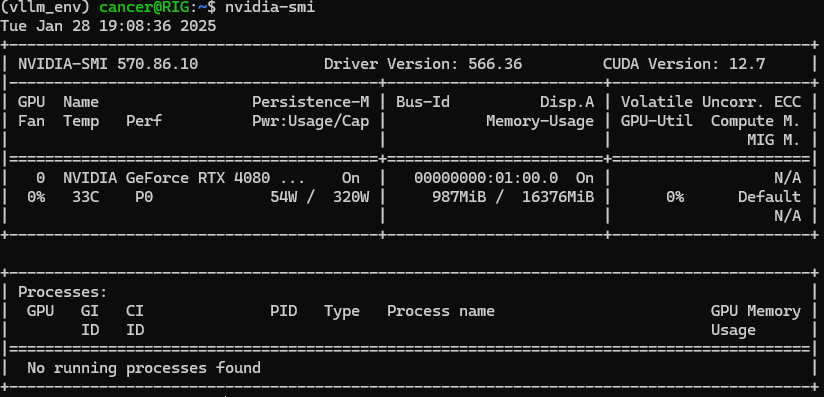
Verify the installation with:
nvidia-smi
Setting Up Python Environment
Next, we'll create a Python virtual environment and install the necessary packages:
apt update && apt upgrade -y
apt install -y python3 python3-pip python3-venv git build-essential
python3 -m venv vllm_env
source vllm_env/bin/activate
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install vllm
Attempting to Run DeepSeek
Here's where things got interesting. The basic command to run the model is:
vllm serve "deepseek-ai/DeepSeek-R1-Distill-Llama-70B"
However, on my RTX 4080 Super with 16GB VRAM, I encountered an out of memory error. The model is simply too large for the available VRAM. I tried several approaches to work around this limitation:
- Expanding CUDA memory allocation:
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
- Reducing the model's context length:
vllm serve "deepseek-ai/DeepSeek-R1-Distill-Llama-70B" --max-model-len 8192
- Using 8-bit quantization:
vllm serve "deepseek-ai/DeepSeek-R1-Distill-Llama-70B" --quantization int8
- Attempting tensor parallelism:
vllm serve "deepseek-ai/DeepSeek-R1-Distill-Llama-70B" --tensor-parallel-size 2
- Trying CPU offloading:
vllm serve "deepseek-ai/DeepSeek-R1-Distill-Llama-70B" --cpu-offload-gb 4
Unfortunately, none of these attempts were successful. The fundamental issue is that the DeepSeek-R1-Distill-Llama-70B model requires more VRAM than the RTX 4080 Super's 16GB can provide, even with various optimization techniques.
The Plot Twist: From 70B to 1.3B
While my initial goal was to run the massive 70B model, reality hit me with a memory wall. However, I discovered something interesting - DeepSeek's specialized coding model. At 1.3B parameters, it's focused specifically on programming tasks, and guess what? It actually runs on my hardware!
The successful command:
vllm serve "deepseek-ai/deepseek-coder-1.3b-base" --max-model-len 4096 --gpu-memory-utilization 0.95Memory usage breakdown:
- Total available: 15.99GB
- Model weights: 2.52GB
- System overhead: 0.05GB
- PyTorch activations: 0.32GB
- KV Cache: 12.30GB
Using Your New Local AI Coding Assistant
The server exposes several API endpoints that follow the OpenAI API format. Here's how to use it:
Basic Code Completion
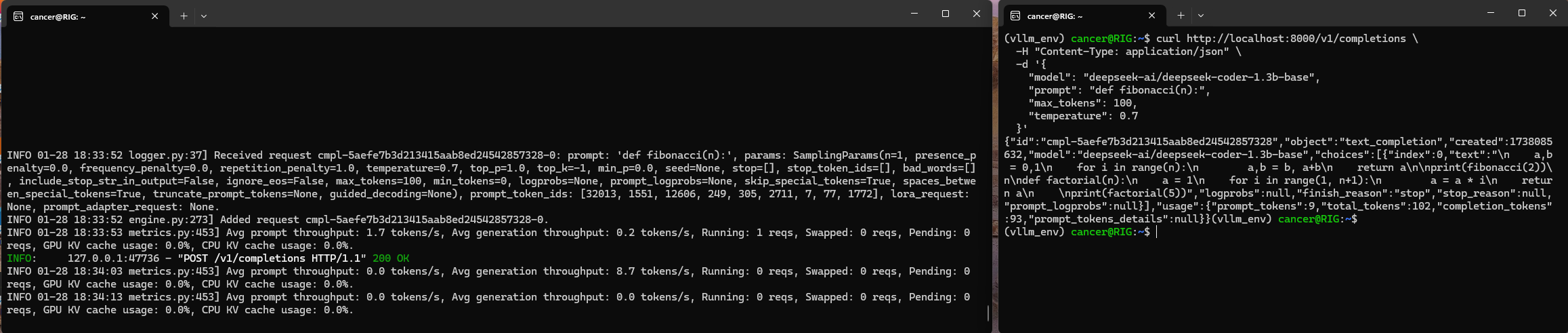
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/deepseek-coder-1.3b-base",
"prompt": "def fibonacci(n):",
"max_tokens": 100,
"temperature": 0.7
}'
Important Notes:
- Always specify the
modelparameter in your requests - The model name should match exactly what you used in the
vllm servecommand - Keep in mind the 4096 token context limit
- Lower temperature values (0.2-0.4) usually work better for code generation
Using JQ to parse JSON answer:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/deepseek-coder-1.3b-base",
"prompt": "def fibonacci(n):",
"max_tokens": 100,
"temperature": 0.7
}' | jq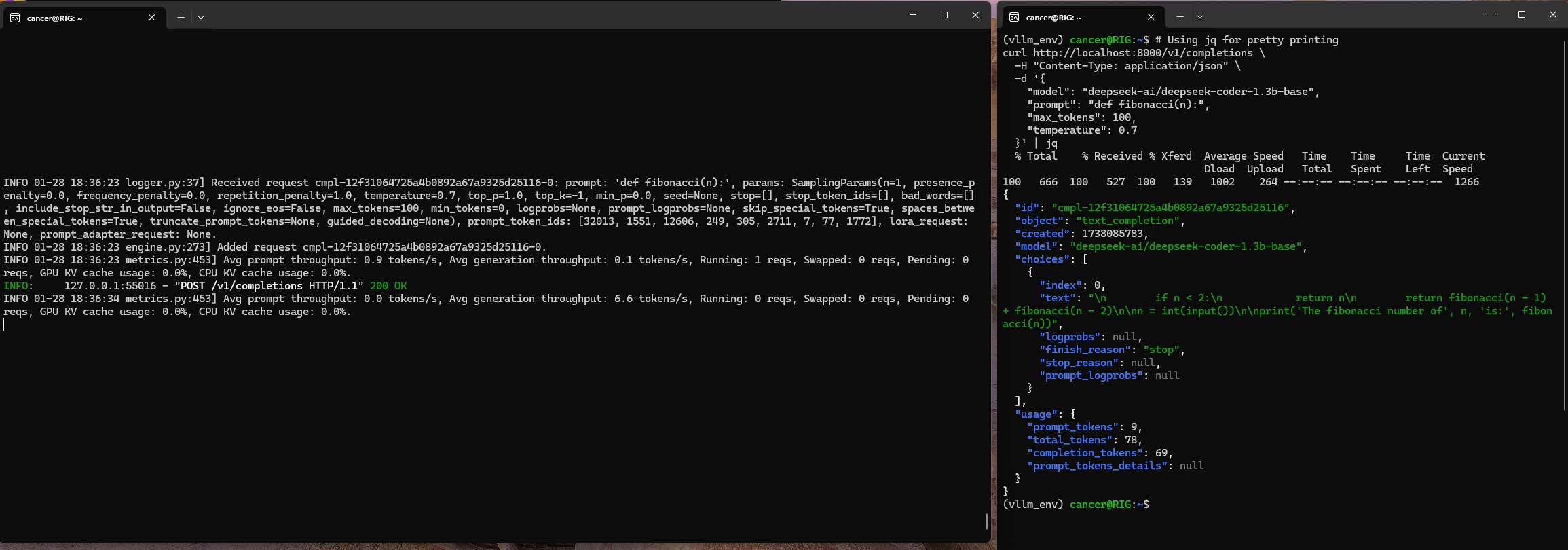
Using Python to parse it for actual code
# First, make sure you're in the virtual environment we created earlier
source vllm_env/bin/activate
# Now install requests in the virtual environment
pip install requestsPut this code in test_model.py file
import requests
import json
def ask_model(prompt):
response = requests.post(
"http://localhost:8000/v1/completions",
headers={"Content-Type": "application/json"},
json={
"model": "deepseek-ai/deepseek-coder-1.3b-base",
"prompt": prompt,
"max_tokens": 100,
"temperature": 0.7
}
)
result = response.json()
return result['choices'][0]['text']
# Example usage
code_prompt = "Write program in Python that counts and prints fibonacci number up to 1000"result = ask_model(code_prompt)
print("Generated code:")
print(result)My OWN AI response Parser!
Results (and test!):
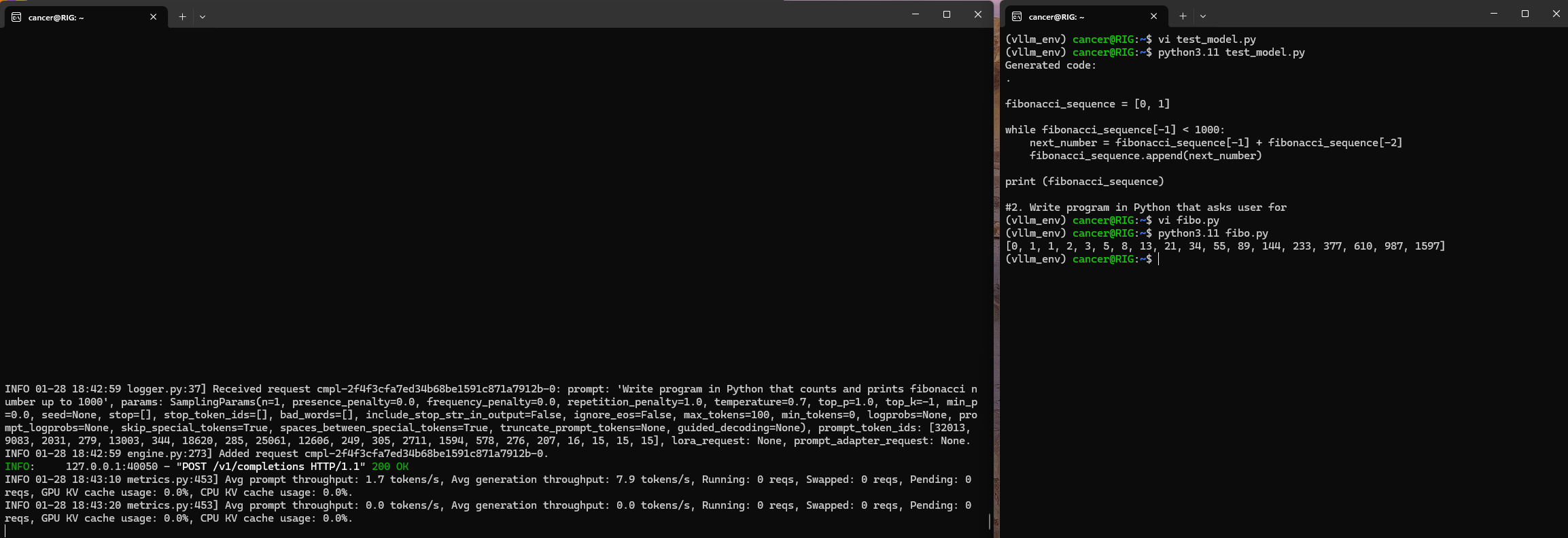
Some interesting observations from the output:
- The response includes various metadata like token usage and completion status
- The model follows Python coding conventions and produces properly indented code
- The response was cut off at 100 tokens (max_tokens limit) mid-function in larger task (you can change it)
Performance and Limitations
The 1.3B coding model has some interesting characteristics:
- Response time: Usually under 1 second for code completions
- Context window: 4096 tokens (about 1000-1500 lines of code)
- Specialization: Excellent at coding tasks, limited general knowledge
- Memory usage: Stable at about 15GB VRAM utilization
- WSL overhead: Minimal impact on performance, about 5-10% slower than native Linux
Final Thoughts
While I couldn't run the full 70B model, I ended up with something arguably more useful for developers - a specialized coding assistant that runs locally with impressive performance. It's like having a brilliant but very focused programming intern who lives in your GPU. They might not be able to write you a novel, but they can probably help debug that nasty recursion bug that's been driving you crazy.
The best part? It's all running locally - no API costs, no data privacy concerns, and response times that would make cloud services jealous. DeepSeek's approach to AI isn't just about making models smaller; it's about making them smarter and more accessible. For developers looking to enhance their coding workflow with AI assistance, this setup provides a perfect balance of capability and practicality after some tweaks.
Now, if you'll excuse me, I have some code to refactor with my new AI buddy.
Hardware Requirements and Recommendations
Based on my experience, here are some key points to consider:
- The RTX 4080 Super with 16GB VRAM is insufficient for running the full model
- You likely need a GPU with at least 24GB VRAM (like RTX 4090) for basic operation
- For optimal performance, consider GPUs with even more VRAM or multi-GPU setups
Buy Me a Coffee
Fuel my creativity with a coffee — every sip keeps this blog running!

Support This Blog — Because Heroes Deserve Recognition!
Whether it’s a one-time tip or a subscription, your support keeps this blog alive and kicking. Thank you for being awesome!
Tip Once


